高併發通用設計閱讀筆記
給自己看方便的閱讀筆記,閱讀材料:
https://zq99299.github.io/note-architect/hc/01/01.html#scale-up-vs-scale-out
高併發通用設計
- scale-out (橫向擴展)
- scale-up (垂直擴展)
- 緩存
- 異步
時間級別
- CPU: ns
- 網卡: $\mu$s
- 硬碟: ms
異步
異步服務範例:請求->(web服務們)->列隊->(隊伍)->異步處理->(處理程序們)
一般系統的演進思路
一開始就千萬級別,連用戶都沒有,怎麼處理?
思路:
- 最簡單的系統設計滿足1. 業務需求, 2. 流量現狀
- 選擇社區成熟的,選擇團隊熟悉的技術體系
- 修小架構無法滿足需求->考慮重構或重寫
架構分層
比如:
- MVC
- 三層架構:數據訪問層->邏輯層->表現層
- OSI
高聚合,低解藕
分層的好處
性能瓶頸直接抽出來單獨部署
如何分層
阿里範例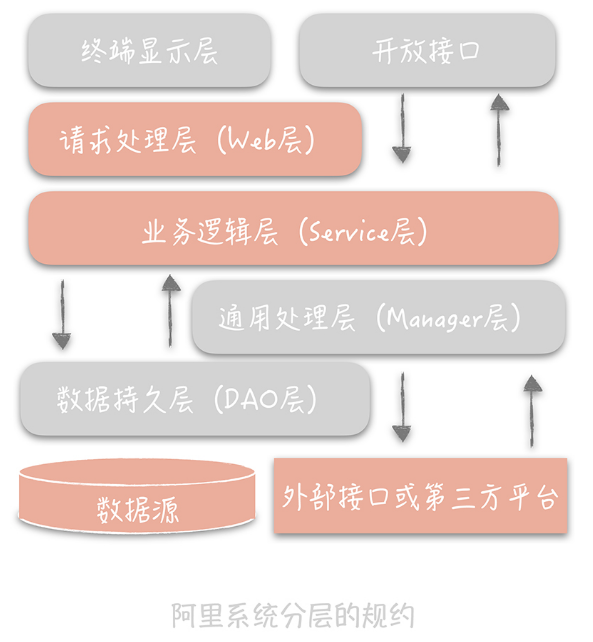
一些原則
- 單一職責原則:一個類一個功能
- 最少知識原則:對其它組件了解盡量的少
- 開閉原則:對擴展開放,對修改關閉
如何提昇系統性能
三高
- 高併發:承擔流量
- 高性能:影響用戶體驗
- 高可用:低停機時間
流量
- 平時流量
- 峰值流量
性能優化原則
- 一定是問題導向,不能盲目
- 82原則
- 實證數據(統計)
- 優化過程是持續的
高併發下的性能優化
提高系統的處理核心數
吞吐量 $\approx$ $\frac{併發進程數}{響應時間}$
拐點模型
在某個臨界點增加併發進程數,因為資源競爭反而造成系統性能的下降。
=> 做壓力測試找拐點
減少單次任務的響應時間
看系統是CPU密集還是IO密集
CPU密集
- 優化算法
- 減少運算次數
- 用Profile工具分析CPU消耗最多的模塊
IO密集
- 用Profile工具分析網路、文件系統、記憶體等
再針對不同的問題選取,scale-out, scale-up, 緩存, 異步等功能
高可用性
度量
- MTBR (Mean Time Between Failure)
- MTTR (Mean Time To Repair)
Availability = MTBF / (MTBF + MTTR)
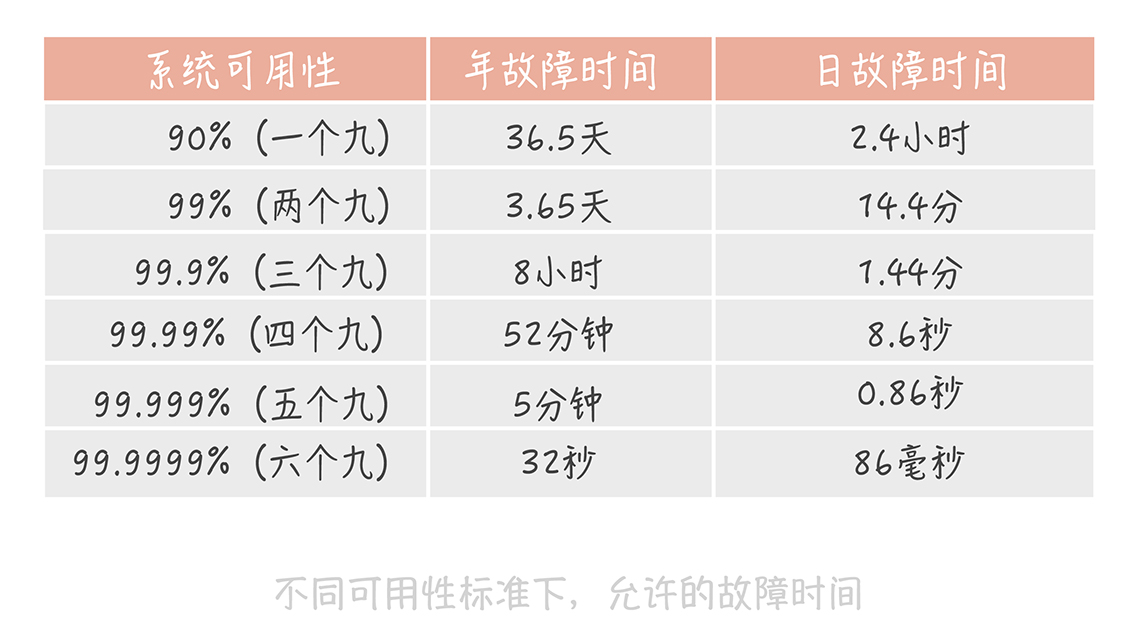
比如:
核心業務: 4個9 (必須要有自動恢復)
非核心業務: 3個9
高可用性的系統設計原則
Design for failure
優化方法
- failover (故障轉移)
- 超時控制:要記log分析,如何算超時合適
- 降級:保證核心服務穩定犧牲非核心服務,比如垃圾訊息檢測
- 限流
系統運維
- 灰度發布:比如先更新10%的機器
- 故障演練:用工具演練硬碟、數據庫、網卡等故障
模擬故障演練
- 網路慢:tc
- 硬碟故障:fiu-ctrl
高可擴展性
問題:
- 峰值的流量不可控
- 瓶頸在系統最弱的一環:比如MySQL較難立即擴展
設計思路:
- 存儲拆分優先考慮業務維度
- 如果還是不夠,依照數據特徵維度再次做拆分
- 拆分後盡量不要使用transactions操作多個數據庫,會需要二階段提交,協調數據庫不具備可擴展性
業務層的可擴展性可從三個維度考慮:
- 業務性質
- 重要性
- 請求來源
備註:
了解組件的實現原理、資料結構、算法…等,對解決系統問題有幫助。
資料庫
池化技術
頻繁的資料庫創造連接會導致響應慢,包含握手和密碼教驗,作者舉例時間可能佔到80%
解決方法:
使用連接池,用空間換取時間
連接池重點設定:
- 最小連接數:10 (經驗性可參考)
- 最大連接數:20~30 (經驗性可參考)
- wait_timeout
池子的預熱
預先進行初始化連接
要注意可能連接池裡的連線不可用
如何檢測連線可用?
select 1
主從讀寫分離
大部分系統讀多寫少
- 主庫寫入
- 從庫讀取
主從複製的流程
由binlog以二進制形式記錄MySQL上所有變化,並且異步的更新到從庫
- 從庫連到主庫,創造IO線程請求binlog,轉寫到
relay log - 主庫創建
log dump線程,發送binlog給從庫 - 從庫創造SQL線程回放relay log,實現一致性
一個主庫大概3~5的從庫
缺陷
主從有延遲,導致可能獲取不到需要的資料
解決方法
- 這麼即時的話,不要從數據庫查,直接在寫主庫的時候一起傳給需要的業務接口
- 從緩存去查
- 從主庫去查 (不能太大)
主從延遲時間是一個關鍵的監控指標
如何訪問數據庫
現在有主庫有從庫,要訪問哪一個可以加個代理層
分庫分表
垂直拆分原則
- 按業務類型拆分,一個功能故障不會全部故障
- 耦合度高的放一起
水平拆分原則
- 依照數據的特點區分
範例:拆分用戶表
分庫分表的問題
- 引入了分區鍵
- 難join
- 主鍵的全局唯一性問題
解決方法
範例:建立ID到user暱稱的映射表
join的問題為了效能也沒辦法,只能拉出來再篩選
主鍵那個問題後面說
分庫分表原則:
- 沒有瓶頸就不用分庫分表
- 如果要做,一次做到位16庫64表,滿足幾年內的業務需求
- 可以考慮用NoSQL替代
分佈式儲存的兩個核心問題
- 數據冗餘
- 數據分片
主鍵如何選擇
- 業務字段 但是業務字段有可能會變化
- 生成唯一ID <- better
為啥不用UUID,UUID的問題
- 不是單調有序,不利資料結構
- 耗費空間
- 不具意義
可使用snowflake
核心思想:有意義的64bit
注意對系統時間有依賴
QPS: Queries Per Second
NoSQL
NoSQL的類型:
- Redis, LevelDB: KV存儲
- Hbase, Cassandra: 以column為主的儲存
- MongoDB, CouchDB: 文檔型數據庫,特點:數據表中的字段可以任意擴展
NoSQL的優勢:
- 性能
- 數據庫變更容易
- 適合大數據
NoSQL適合與SQL互補,比如倒排索引,由分詞出關鍵詞對應回ID
NoSQL的擴展性
- Replica:主從分離,但若是主掛了,會有其它節點補上
- Shard:分片,NoSQL的分庫分表,在MongoDB,需要三個角色來支持
- Router
- Config Server
- Shard
緩存
緩存:協調兩者數據傳輸速度差異的結構
緩存案例
linux記憶體管理,使用MMU實現虛擬到物理地址轉換,但是計算複雜,會用TLB來緩存最近轉換過的映射
HTTP,獲取圖片和Etag,下一次request,If-None-Match: Etag,server回304
緩存分類
- 靜態緩存:用於靜態資源
- 分佈式緩存:用於動態請求
- 熱點本地緩存:是在應用服務器中,用於極端的熱點數據查詢,HashMap, Guava Cache, Ehcache,有效期短,不能確定是哪台服務器做緩存
緩存的不足
- 比較適用於讀多寫少的應用,數據有熱點需求
- 數據不一致性,可能更新資料庫成功,更新緩存失敗
- 常用內存當緩存,但內存也不是無限的
- 增加系統複雜度,運維成本增加
Cache Aside 策略
解決緩存與數據庫中的數據不一致
讀策略:
- 從緩存讀數據
- 緩存命中,返回數據
- 緩存不命中,從數據庫讀
- 寫入緩存,返回用戶
寫策略:
- 更新數據庫
- 刪除緩存
其實還是有可能數據不一致,但是因為緩存寫入快,所以機會低
要注意根據應用場景而變,比如說,註冊新用戶,因為主從分離,會因為主從延遲而讀不到用戶信息
這時候就是要寫入數據庫後寫緩存,且因為是新用戶,所以不會有併發更新用戶資訊的情況
Cache Aside的問題
寫入頻繁時,緩存會頻繁被清理
兩種解決方案:
- 更新數據也更新緩存,只是在更新緩存前先加個分布式鎖,只允許同時間有一個線程更新緩存
- 更新數據時,加一個短過期時間,緩存不一致會很快過期,業務上可接受的話就ok
Read/Write Through策略
用戶只與緩存打交道,由緩存和數據庫通信,寫入或讀取數據
Write Miss
寫請求的數據,在緩存中不存在
Write Allocate
寫入緩存,由緩存組件更新到數據庫
No-write Allocate
不寫入緩存,直接更新到數據庫
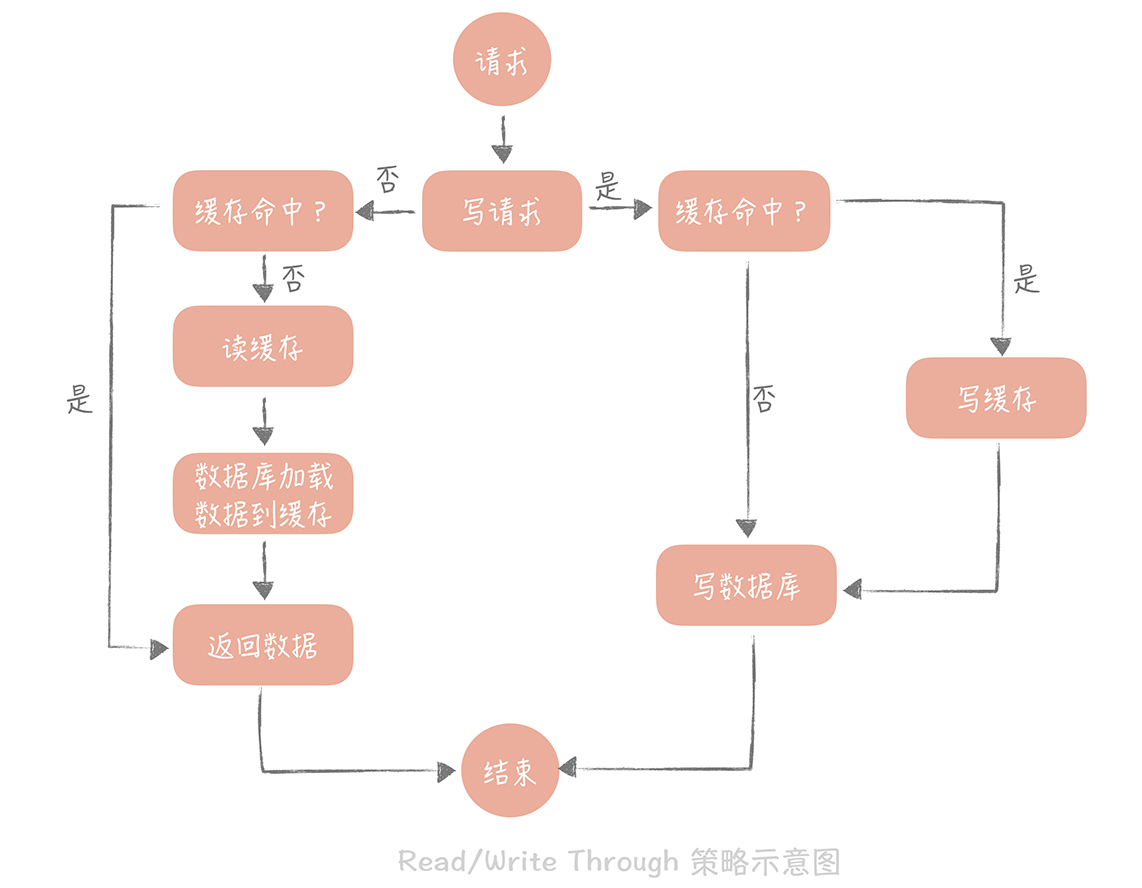
像是Redis, Memcached不提供寫入數據庫,或自動加載數據庫中數據的功能
要注意是同步寫數據庫,對性能有影響
Write Back策略
寫數據只寫緩存,並把緩存區塊標為dirty
對Write Miss使用Write Allocate
寫策略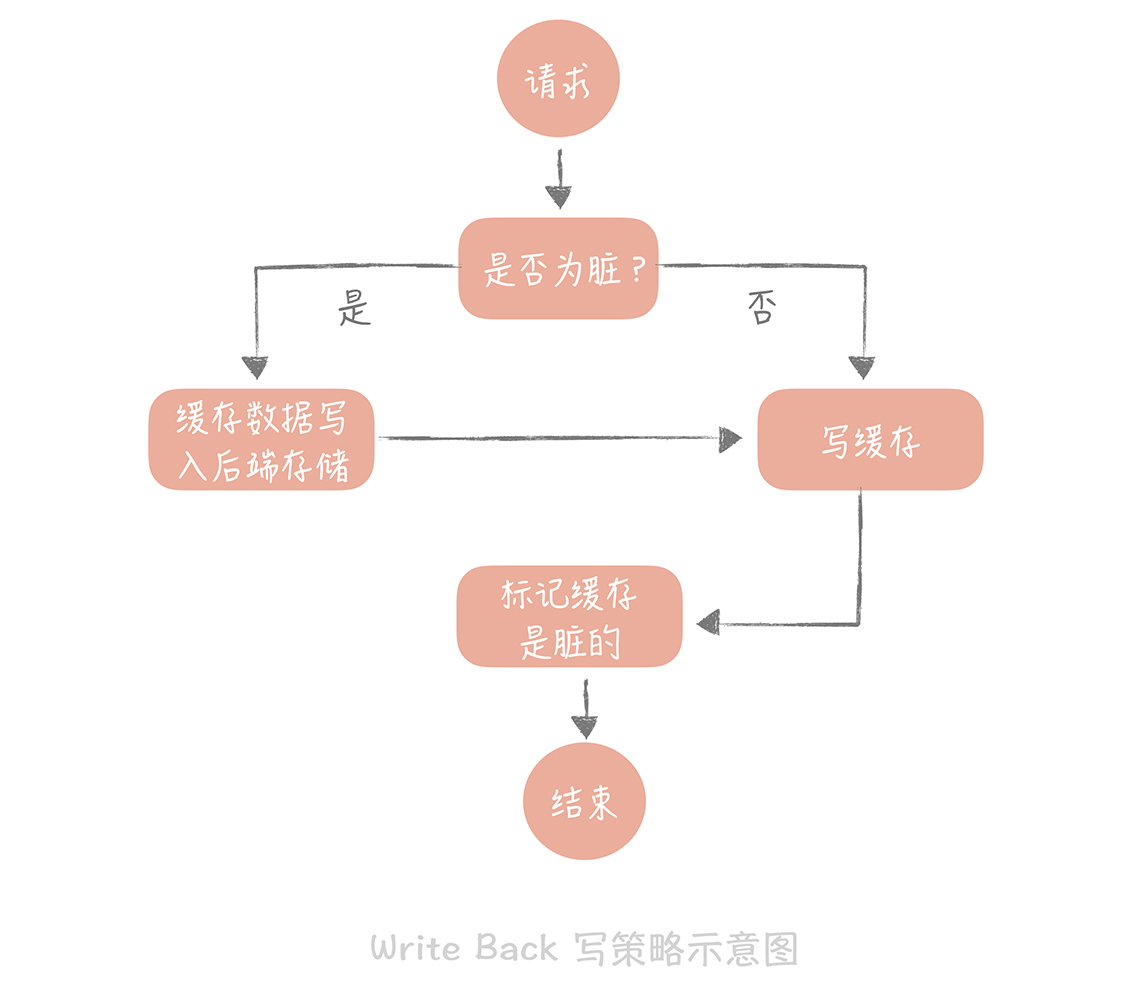
讀策略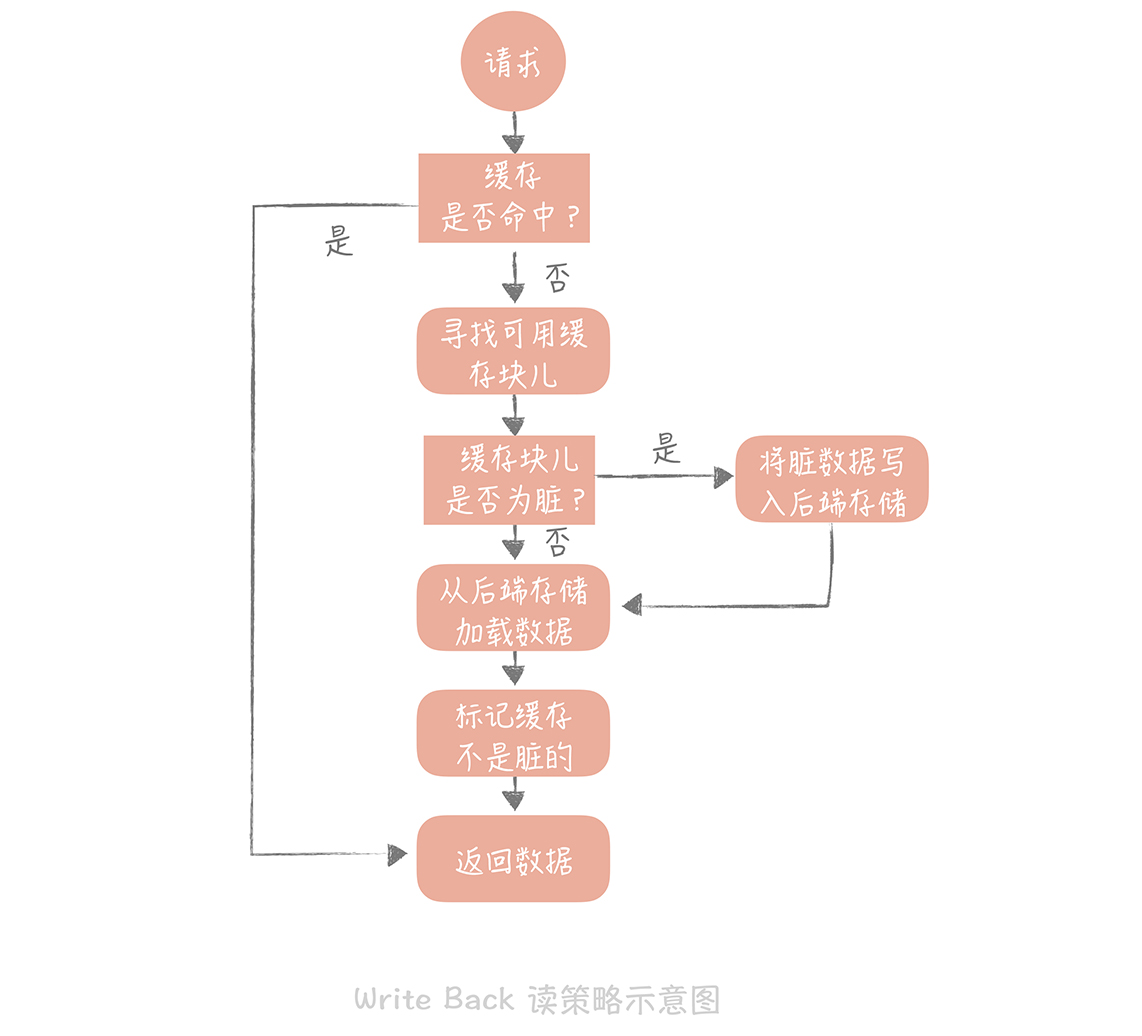
這個策略用於向硬碟寫數據,難以應用到常用的數據庫和緩存的場景,因為緩存如果是記憶體,是非持久化的。
緩存如何高可用
緩存高可用有多重要?
緩存命中率 = $\frac{緩存命中數}{總請求數}$
核心緩存的命中率需要維持在99%甚至是99.9%,下降1%,系統會遭受毀滅性打擊。
範例:
QPS: 10000/s
每次調用會訪問10次緩存或數據庫
緩存命中率減少1%
10000 * 10 * 1% = 1000次請求
單個MySQL節點的讀請求量1500/s
1000次請求可能會對數據庫造成衝擊
解決方法:分佈式緩存
分佈式緩存的高可用方案:
- 客戶端方案:客戶端配置多個可連線的緩存節點
- 中間代理層方案:代碼和緩存節點間增加代理層
- 服務端方案:Redis > 2.4, Redis Sentinel
客戶端方案
透過制定分片策略和數據讀寫策略 e.g. Hash,實現分佈式高可用
好處是性能耗損低
壞數客戶端邏輯複雜,多語言無法復用
中間代理層方案
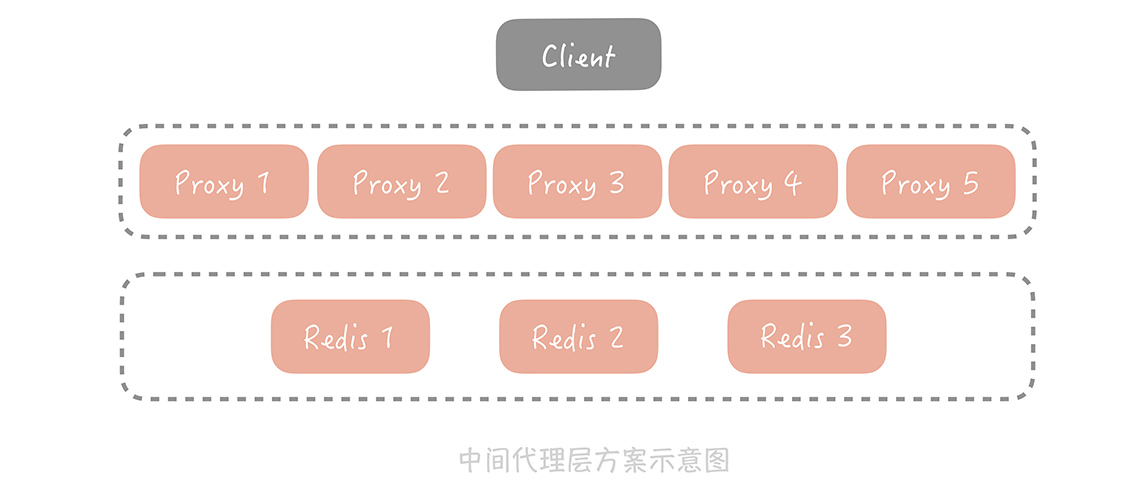
Facebook的Mcrouter
Twitter的Twemproxy
服務端方案
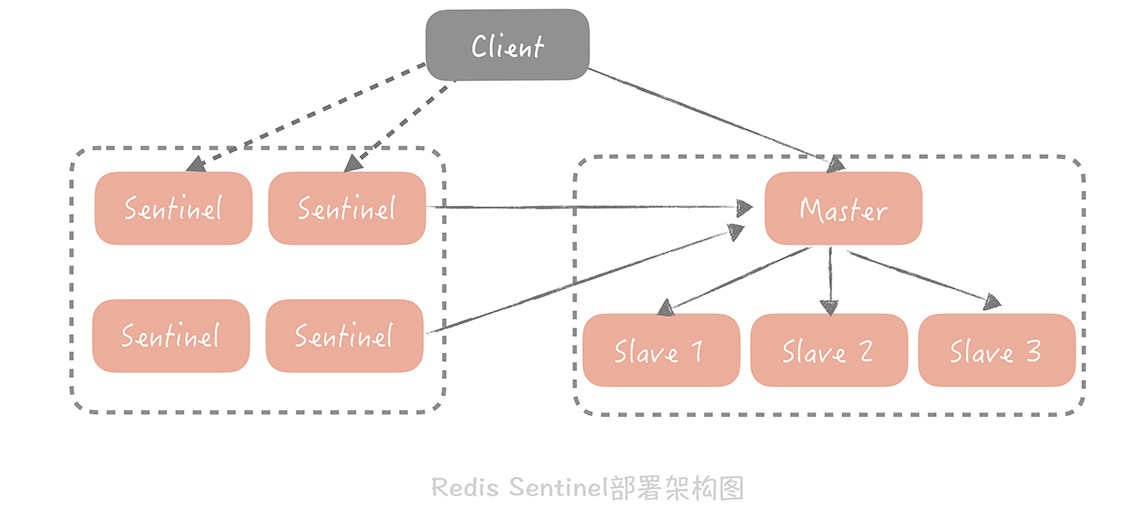
緩存穿透
緩存穿透指的是緩存沒查到,不得不去查詢後端系統
範例:
找不存在的用戶ID資料,保證cache會失敗,一直查資料庫
解決辦法:
- 回種空值:對於查詢把空值放在緩存
- 布隆過濾器:判斷元素是否在集合中
布隆過濾器:
元素經過hash並mod目標可能總數,如果為1就查緩存或是穿透,0就不在集合,直接回應
只會有false positive,沒有false negative,不是就一定不是,比如判斷不是用戶就不是用戶
但是因為布隆的hash計算方式有可能發生碰撞,所以還是可能穿透
優化使用多個hash算法計算,如果都為1才認為在集合中
問題:
不支持刪除元素,因為碰撞的問題
Doge-Pile effect
一個熱點緩存失效,導致大量穿透
解決方法
- 失效後啟動線程,加載數據庫數據到緩存,未加載前所有請求不再穿透直接返回
- 在Memcached或Redis設置分佈式鎖
2的做法,在Memcached寫入key為lock.1的緩存,加載後刪掉,後面的若看到有lock.1就重新在緩存取數據
靜態資源的緩存
用CDN,重點是就近訪問
CDN第三方會給CDN的IP
問題:那如果換CDN的第三方廠商呢?或是換IP呢?
解決:
CNAME 跳到另外一個域名
比如自己機構的圖片域名:img.example.com
把CNAME配置為a1b2c61.cdn.company.com
DNS域名解析本身可能很久
域名解析流程:
- 本地hosts文件
- Local DNS
- 請求根DNS 返回.com
- 請求.com頂級DSN返回 google.com
- 從google.com的域名服務器查到www.google.com的ip,返回ip標記來自權威DNS,寫入Local DNS做緩存
繞過得方法:App先預先解析,並存緩存,且有定時器定期更新
如何找到離用戶最近的CDN節點
GSLB
比如按照IP劃分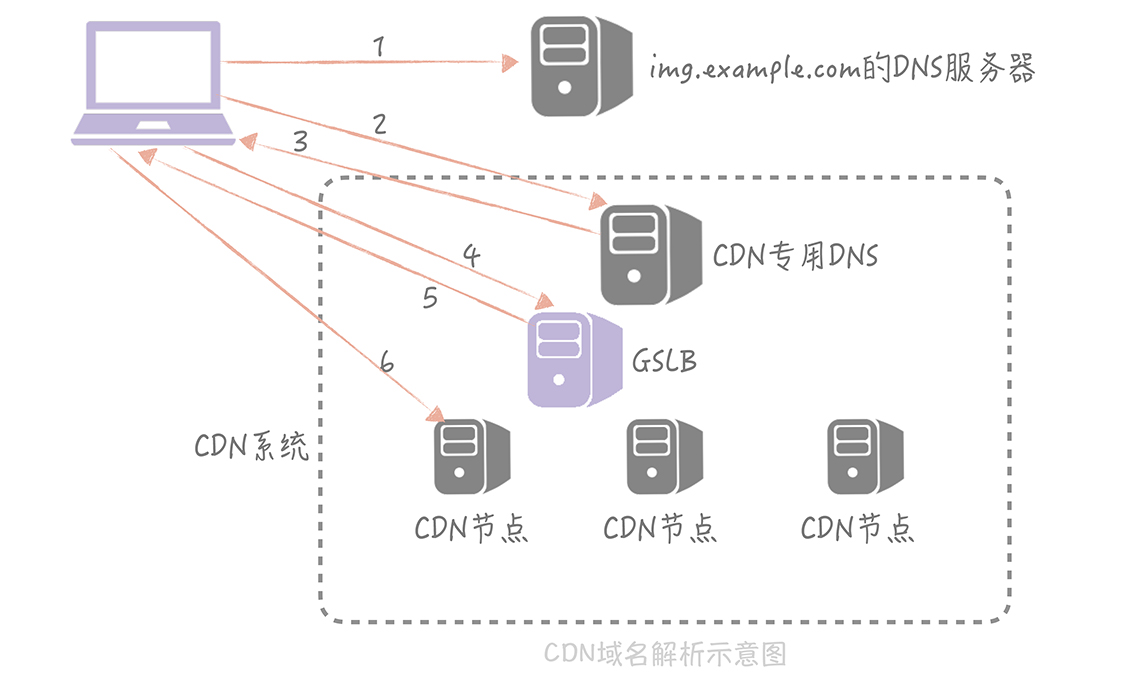
數據遷移
數據遷移的重點
- 在線遷移,遷移的同時有可能寫入
- 數據的一致性
- 可以輕易回滾
- 預熱cache,不然資料庫可能直接爆了
雙寫方案
- 新庫配置為舊庫的從庫
- 數據寫入的時候兩邊的都要寫入,可以異步寫入新庫
- 抽樣校驗數據
- 灰度切換,也可預熱快取
- 有問題就切換回舊庫
自建機房遷移到雲上要盡量自建服務用自建資料庫,雲上服務用雲上資料庫減少流量
消息列隊
一般情況都是讀多寫少,但如果有高併發寫請求,比如秒殺搶購呢?
解決:使用消息隊列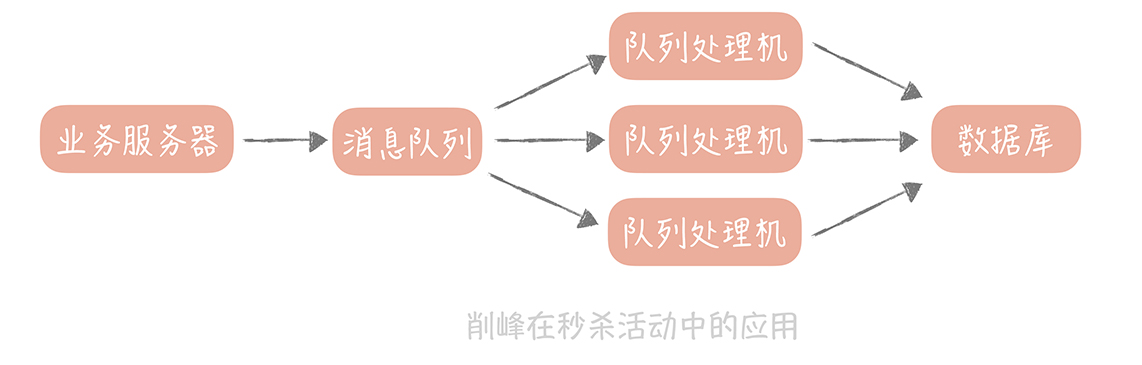
要考慮的問題
- 同步流程和異步流程的邊界
- 消息是否丟失,是否重複?
- 請求的延遲是多少?
- 業務流程能否分散到不同消息列隊?
消息為什麼丟失
主要有三種場景:
- 消息從生產者寫入到消息列隊
- 消息在消息隊列存儲
- 消息被消費者消費
生產傳到列隊前丟失
網路抖動
處理方式:消息重傳
但是可能造成重複
消息隊列中丟失
比如:Kafka會先寫到page cache,然後適當時機再到硬碟上,像是某一時間間隔,即異步刷盤,但掉電就GG了
處理方式:以集群方式佈署Kafka
消費過程丟失
網路抖動或業務異常
如何保證消息只被消費一次
解決方法:保證消息的冪等性
Kafka >= 0.11 和 Pulsar 有 producer idempotency 特性
生產過程的冪等性
生產端
Kafka給生產者唯一ID和消息唯一ID
消費端
生產時發號器給全局ID,消費時檢查,處理後記錄處理過ID
問題:消息處理後來不及寫數據庫又重複
解法1. 需要引入transaction保證同時成功或失敗(要求嚴格的話)
解法2. 引入樂觀鎖 version = 1 = 2…
消息的延遲
如何監控消息延遲
- 生成監控消息:直接把ts包成消息丟到隊列,業務處理到時,如果時間差達到某一閥值就發警報
- 內建的監控工具,看延遲幾個消息
建議兩者都用
如何減少消息延遲
- 優化代碼提昇消費性能
- 增加消費者的數量 (卡夫卡1個topic可多個分區,每個分區只能有1個消費者)
- 消息的存儲: memory, disk, or db on disk
- 零拷貝技術
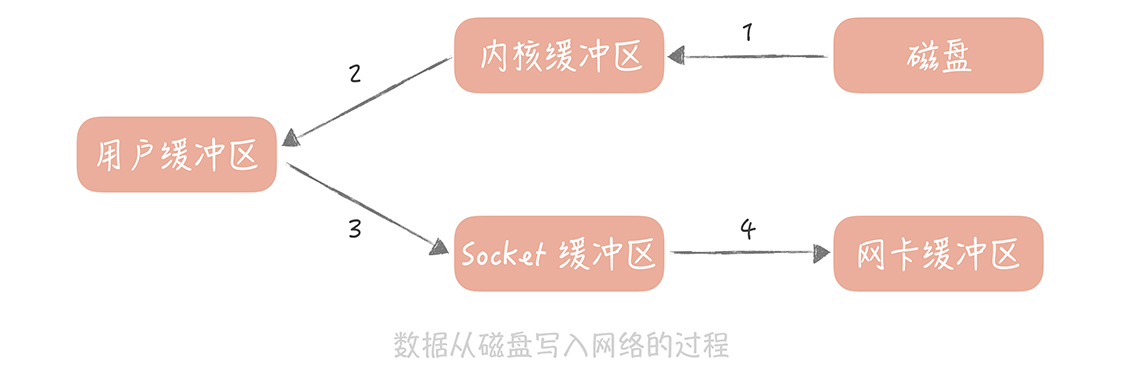
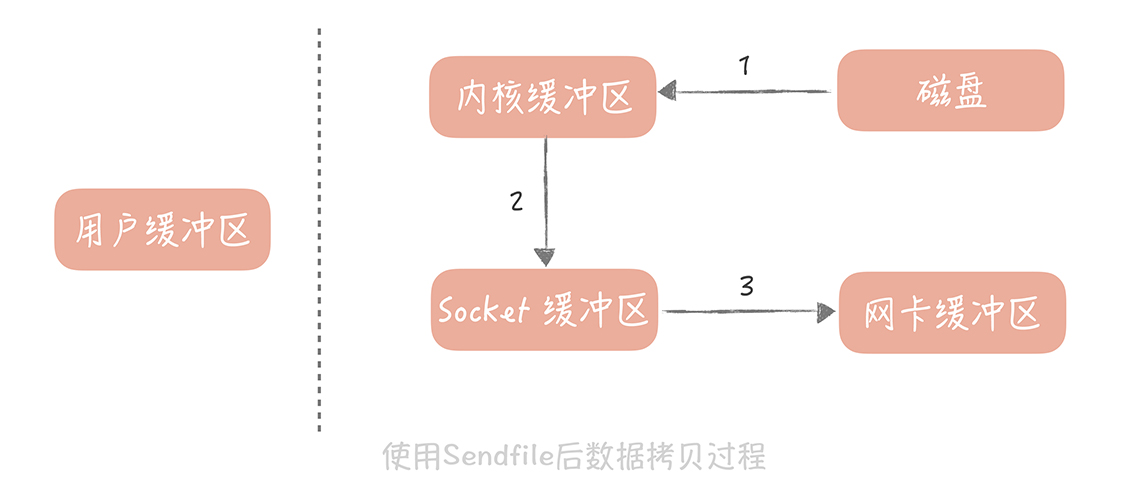
小建議,也要考慮隊列為空,消費端不可過於頻繁拉消息
補充
buffer是減少調用次數,集中調用來提昇系統效能
cache是將讀取過的數據保存,後續命中來提昇系統效能
user mode
kernel mode 可執行Privileged Instruction
- I/O instruction(I/O protection)
- Base/limit register值修改(Memory protection)
- Time值修改(CPU protection)
- Turn off interrupt
- Switch mode to kernel mode
- Clear Memory
微服務
目前看的方法都是一體化架構
解決方法是把一體化架構拆分成微服務
拆分原則
- 高內聚低耦合
- 可擴展性
要注意的地方
- 服務間靠的是網路調用
- 多個服務可能會有依賴關係,要有服務治理體系,如熔斷、降級、限流、超時等方法
- 問題定位,性能瓶頸分析
- 監控服務的資源和宏觀性能表現
康威定律:設計系統的組織等同於組織間的溝通結構
RPC框架
RPC調用過程
- 類名、方法名、參數名、參數值做序列化成二進制流
- 客戶端將二進制流送給服務端
- 服務端做反序列化,並調用方法得到返回值
- 將返回值序列化,發給客戶端
- 客戶端對返回結果反序列化,得到結果
所以優化RPC可以從兩個方向著手
- I/O
- 序列化
網路傳輸優化中,首先要選擇高性能的I/O模型
I/O分兩階段
- 等待資源階段
- 使用資源階段
等待資源階段可分成
- 阻塞
- 非阻塞
使用資源階段可分成
- 同步處理
- 異步處理
I/O模型分5種
- 同步阻塞
- 同步非阻塞
- 同步多路I/O復用:等待多個資源,哪個好了就先用
- 信號驅動I/O:資源有了就提醒
- 異步I/O:資源有了就自動做事
最廣泛使用的是多路I/O復用
要重視網路參數的優化
範例:tcp_nodelay為true
接受緩衝區、發送緩衝區大小
客戶端請求緩衝隊列的大小
序列化協議的選擇
- XML
- JSON
- Thrift: facebook的,含RPC框架
- Protobuf
Thrift和Protobuf高性能
Protobuf比JSON省空間
註冊中心:分佈式系統服務發現的問題
Naive: 把服務器位置記錄下來
但是難以動態變化
使用註冊中心
範例:
- ETCD (ZooKeeper, Kubernetes使用)
- Eureka (Nacos, Spring Cloud)
註冊中心的基本功能
- 服務地址的存儲
- 內容變化時推送給客戶端
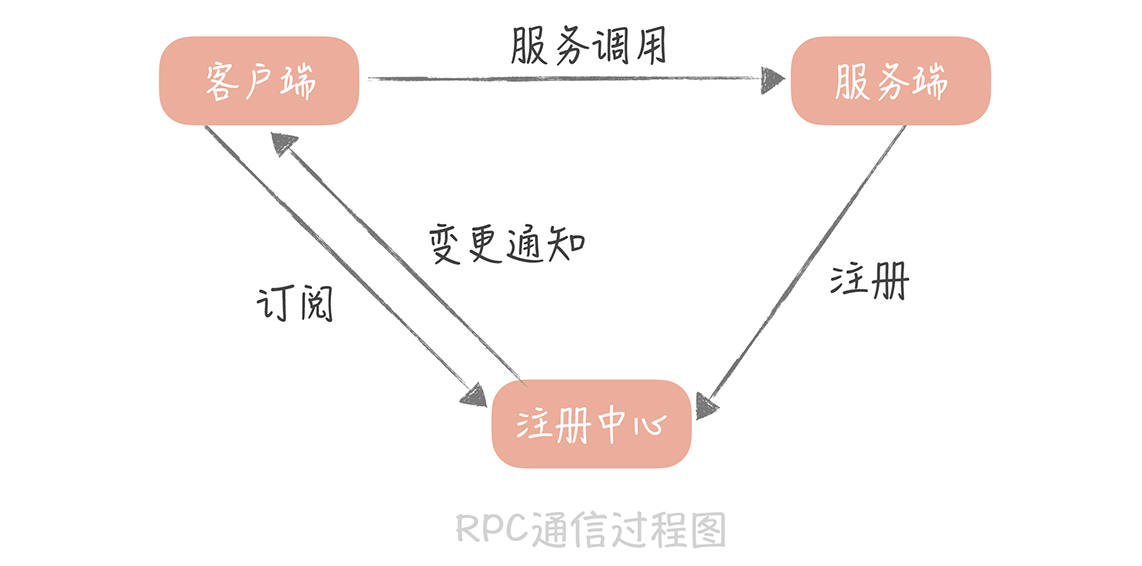
問題:如果服務端故障,怎麼從註冊中心移除?
解決方法
- 主動探測
- 心跳
問題二:這些方法在某些情況可能導致服務全部被摘除
解決方法
- 設置閥值,比如40%的節點被移除,發出警報
問題三:通知風暴,100個調用者,100個節點,節點變更總通知數為100*100
解決方法
- 註冊中心集群
- 有必要通知再通知
分佈式trace
log的處理
- requestId將日誌串起來
- 減低代碼侵入性, e.g. python decorator
- 日誌採樣
- 上傳日誌,集中管理
微服務架構可以記錄調用順序
負載均衡
可分兩類
代理類:LVS(QPS高,Web服務), Nginx(QPS 10萬內, Web服務HTTP協議)
上述兩個不適用微服務,微服務走RPC客戶端:
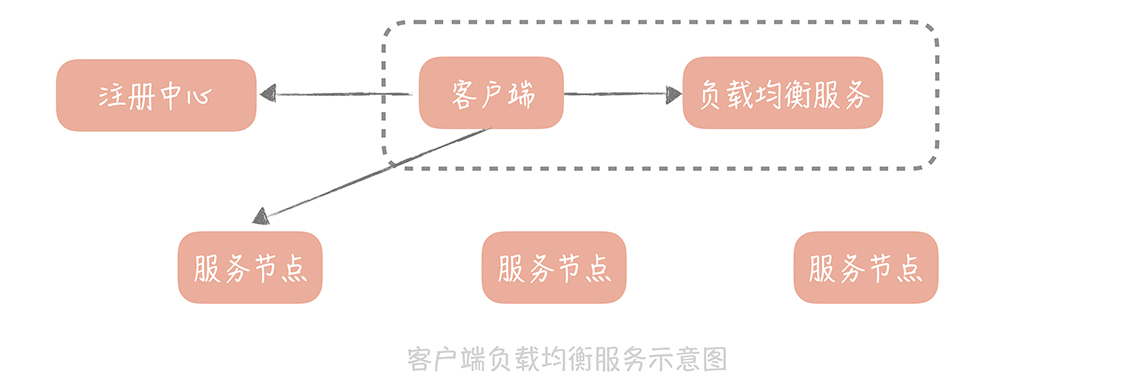
負載均衡策略
- 靜態策略:不參考實際運行狀態,e.g. 輪詢(RoundRobin, RR)、權重RR(依照性能)、ip, url hash…等
動態策略 - 動態策略:考慮server狀態
問題:如何保證配置的服務節點可用?
範例
nginx_upstream_check_moduleL:定期探尋返回狀態碼
web服務的優雅啟動與關閉
初始化期間默認HTTP 500,這樣就不會一下就標記為可用
完成初始化HTTP 200
關閉時設置HTTP 500,被探測不可用之後,流量就不會發往這個節點,確認無流量後,服務關閉或重啟
API gateway
引入API gateway的好處:API限流、跨語言
分兩類
- 入口gateway:對外暴露做服務治理,熔斷、降級、流量控制、分流,或是做認證、黑白名單、生成requestID
- 出口gateway:依賴第三方系統,調用外部API,認證、授權、審計訪問控制
API gateway性能關鍵I/O模型,使用I/O多路復用 (I/O multiplexing)
實作選擇
- Netflix的Zuul 2.0
- Kong
- Tyk
架構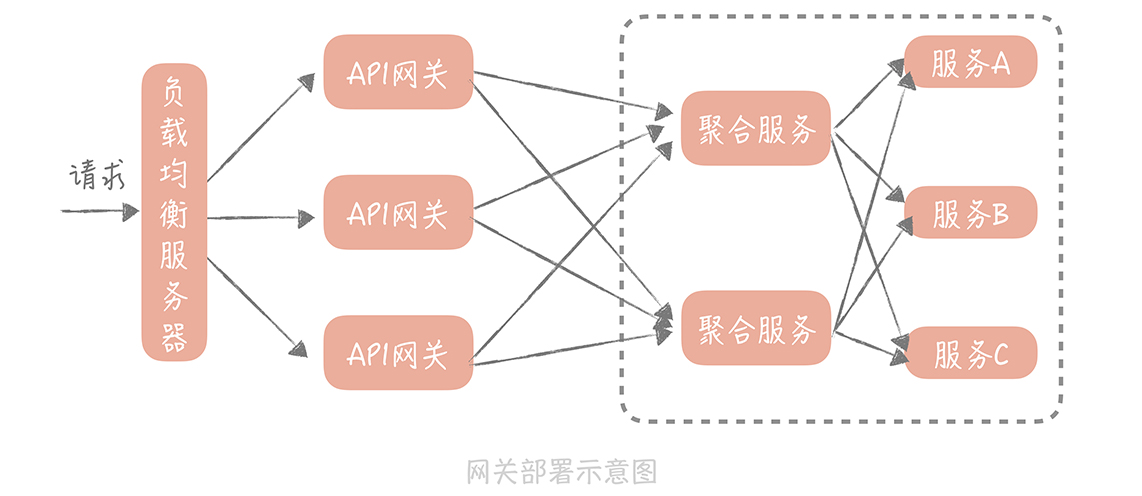
考慮跨地域的可用性
- 同地雙機房延遲1ms~3ms
- 異地雙機房延遲10~50ms
- 跨國100~200ms
跨機房多活可用性
- 同地可以在資料庫做同步
- 異地可以在消息隊列做同步
Service Mesh
處理微服務間通信的基礎設施
istio範例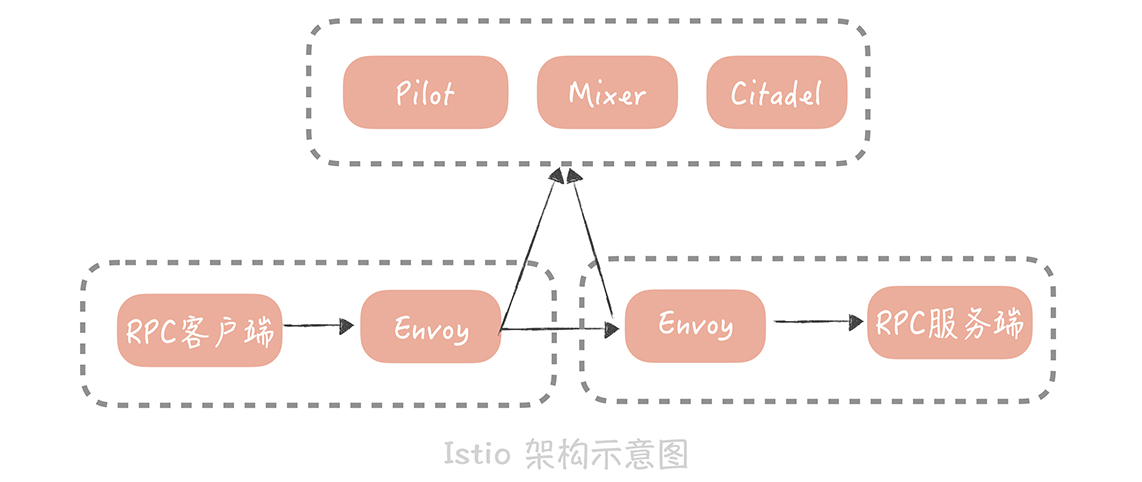
裡面的組件分為
- 數據平面:sidecar協助RPC client間通信
- 控制平面:服務治理策略
iptables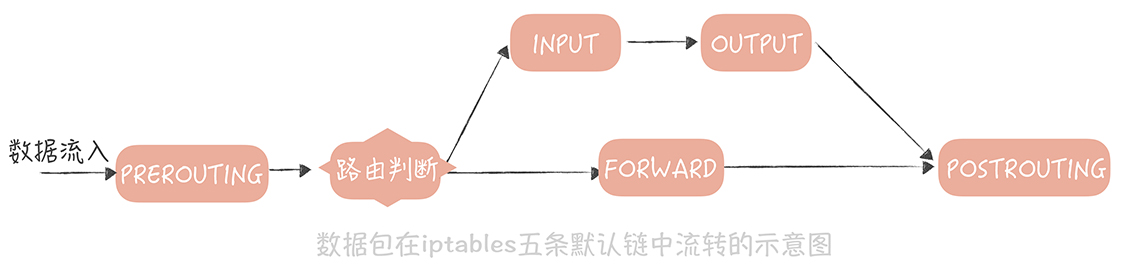
Service mesh需要無感知的引入sidecar作為網路代理,做法是數據流入流出都會將數據包重定向到sidecar端口
監控
監控指標
- 延遲
- 通信量
- 錯誤
- 飽和度
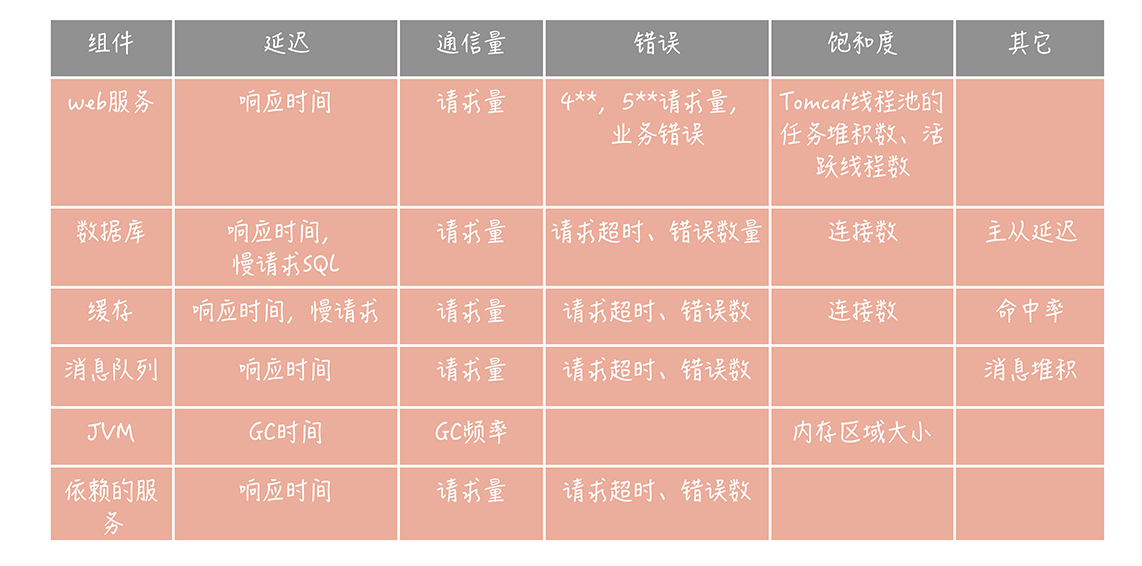
採集數據指標
可以從訪問日誌、系統日誌收集
也可選擇平台對應的收集工具像Apache Flume、Filebeat
要注意可以不要造成監控server太大負擔,可以每10秒聚合一次消息發過去
監控數據的處理和存儲
將數據存儲在時間序列資料庫
常用的time-series db有influxDB, OpenTSDB, graphite
最後可以用Grafana呈現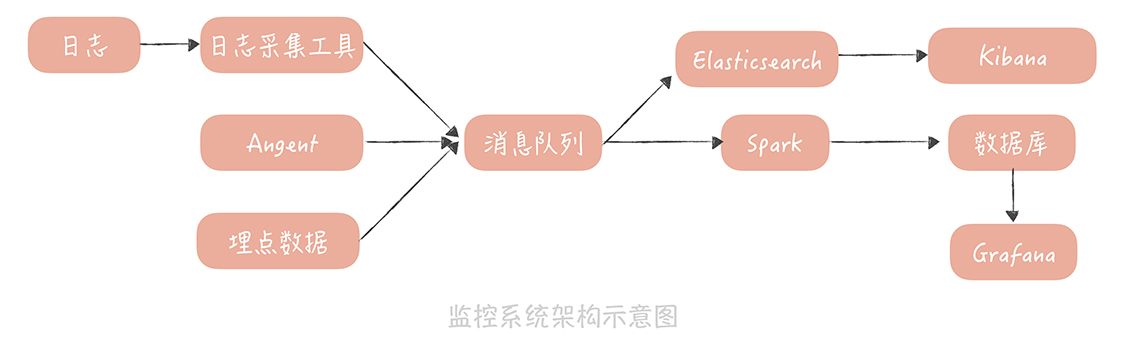
形成報表
- 訪問趨勢報表
- 性能、資源報表
應用性能管理(APM)
監控用戶體驗數據,需要考慮
- 版本號、header
- timestamp, signature
- 機器型號, SDK版本號, 網路類型, ISP, 國家地區…
- 業務內容的性能數據,比如網路傳輸過程的時間
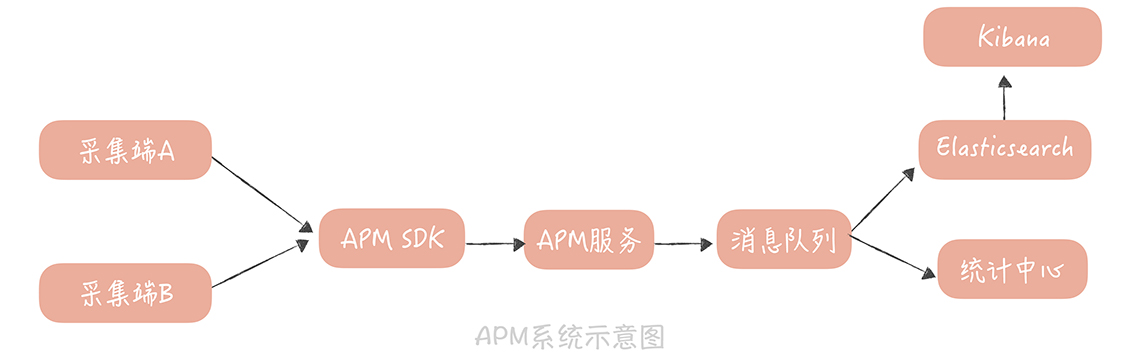
壓力測試
重點
- 最好使用線上環境
- 考慮緩存,要模擬正確的資料分佈
- 從多台服務器發起流量,離用戶近一點
目標:找到整體調用鏈的性能隱患與能力上限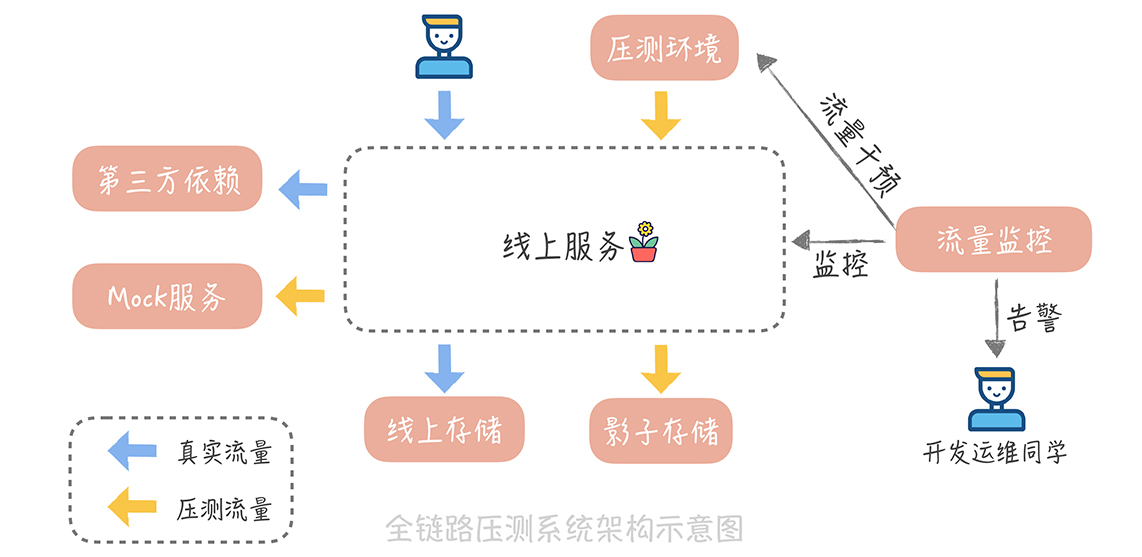
開源流量拷貝工具GoReplay,可加速回放
可以在HTTP header加說這是壓測
要考量的點
- 對真實與壓測讀寫的流量都做隔離
- 讀取部份:可對某些組件做特定處理,比如讀商品 不能算做真實流量
- 寫入部份:創建影子db,可把真實數據都導入
- 預先設定壓測目標且符合業務目標,慢慢加上去
配置管理
- 配置中心
- MD5去檢查設定是否有更變
- 配置策略:論詢或長連
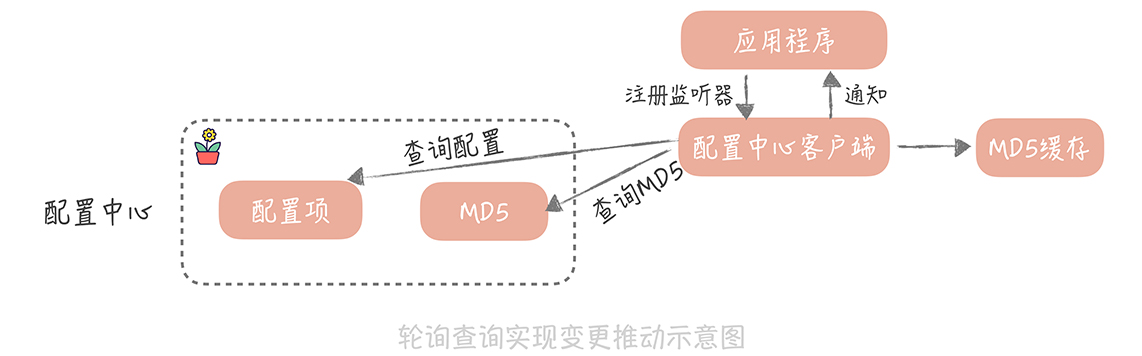
- 考慮配置中心當機,可本地緩存
降級怎麼做
可以設定開關,例如
1 | boolean switcherValue = getFromConfigCenter("degrade.comment"); // 从配置中心获取开关的值 |
限流
拒絕服務保證可用性
限流算法
- 固定窗口 10000/min
- 滑動窗口
- 漏桶算法
- 令牌算法 (推薦) N/s 那每隔1/N秒就增加1個可取用token
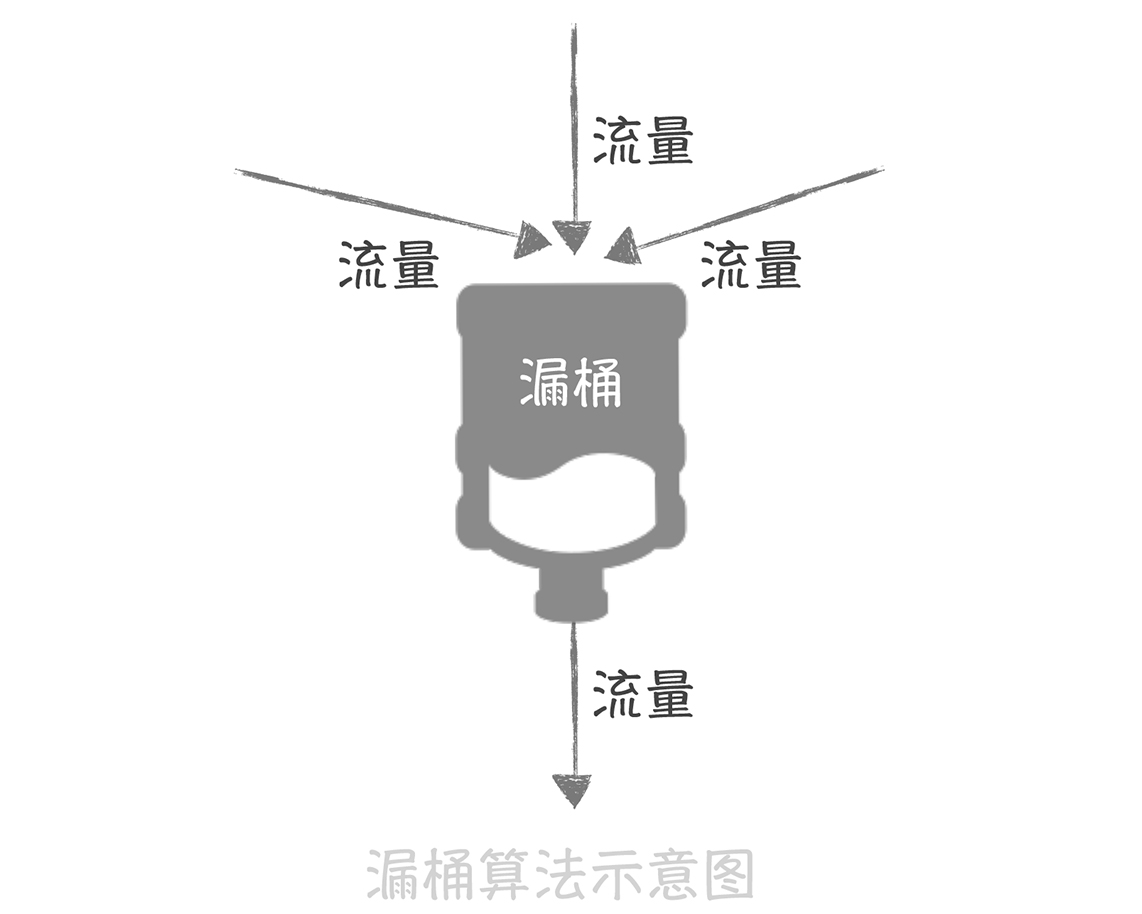
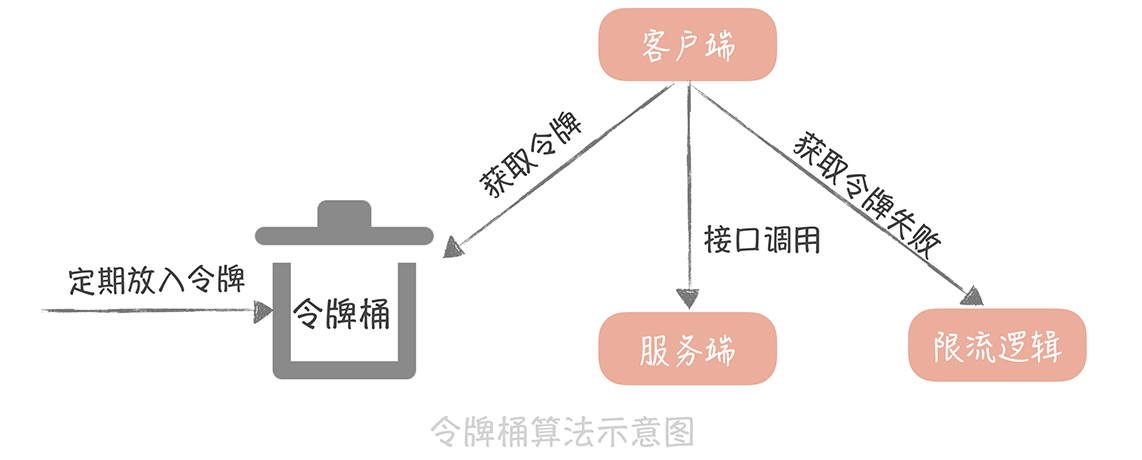
補充:出現time_wait,系統會有最大生存時間,可能會塞滿,應該要確認程式是某有優雅的關閉TCP連接,才來考慮限制最大time_wait數量或時間
System Architecture
綜合以上,一體式架構可以變成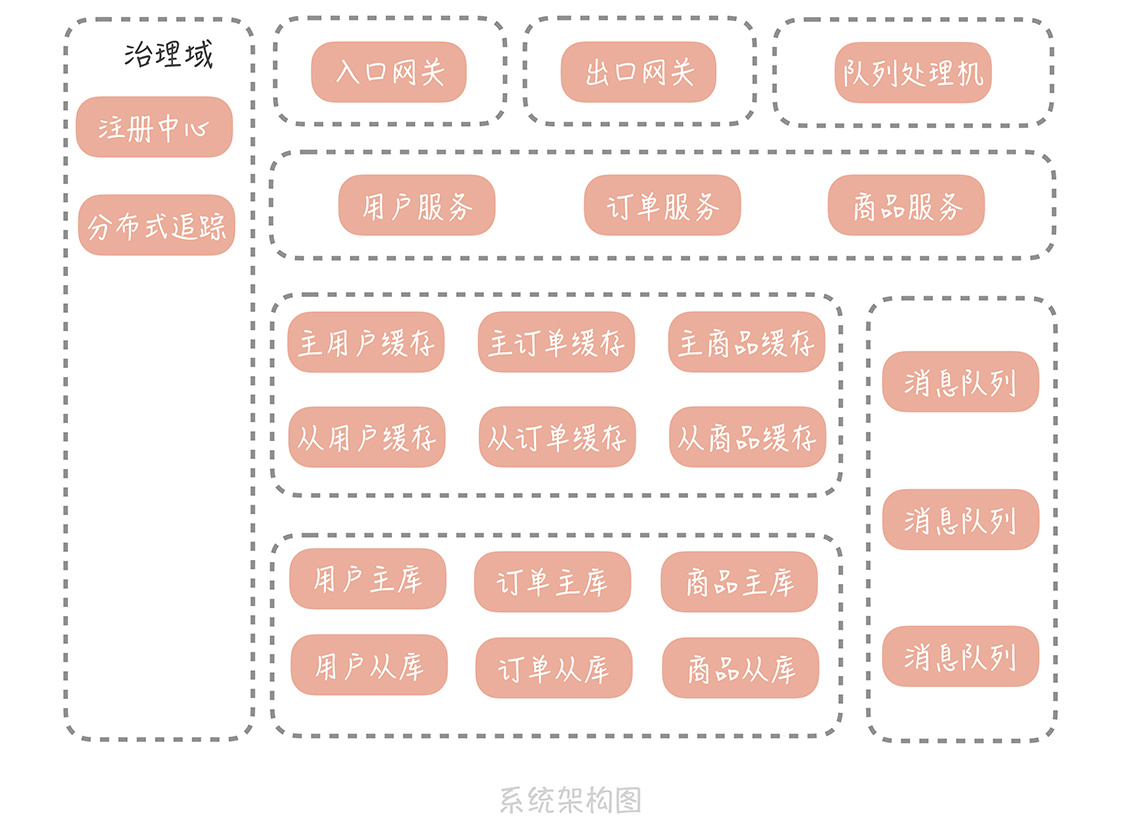
實戰
計數系統演進範例
MySQL -> + hash -> 多個Redis -> + 消息隊列 -> + SSD
未讀數系統
記錄已讀ID或是user ts, 後面就是未讀的消息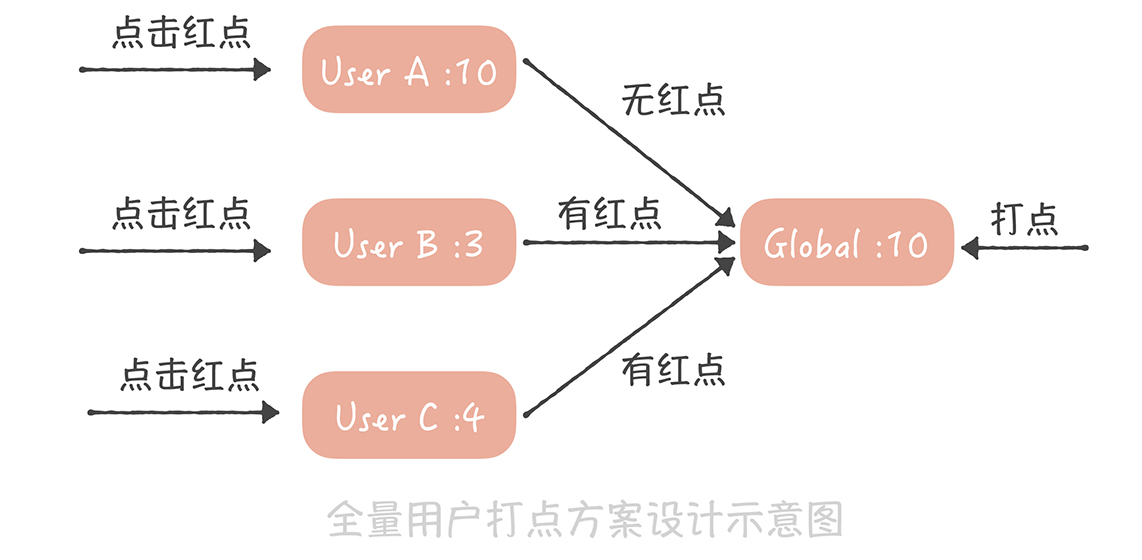
如果是用戶A關注了,B, C, D,用戶的未讀數怎記錄?快照B, C, D,相減A的已讀B, C, D數之總和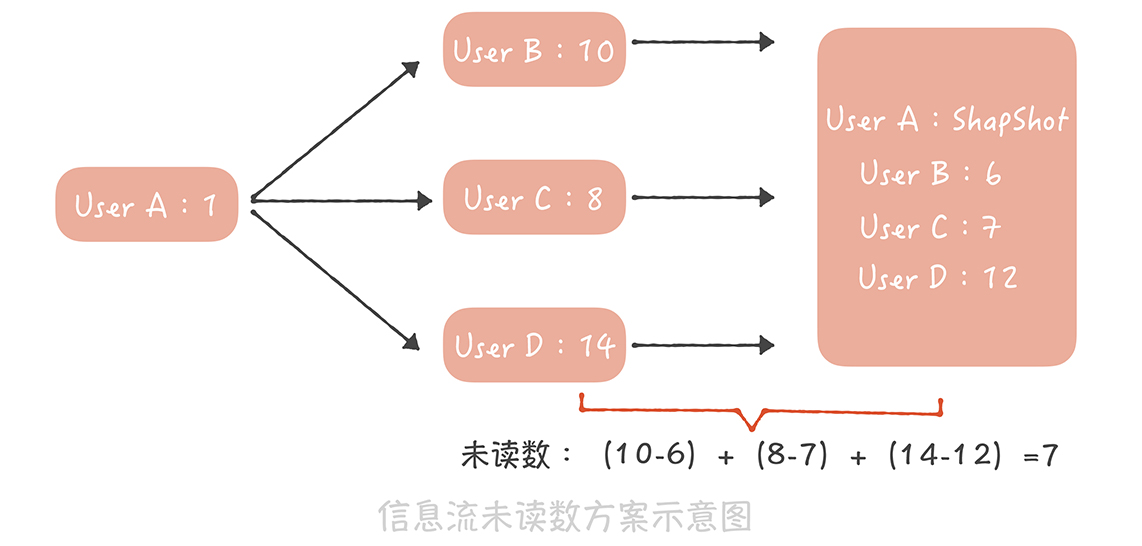
信息流推模式
每一個人都有一份收件箱
一個人發了消息,發通知到訂閱者
適合5000人左右e.g. 朋友圈
信息流拉模式
發消息的人寫消息到自己的發訊息箱
要推送的人request的時候再去拉訂閱的目標並聚合